An “edit” button for Twitter has often been requested, and on the surface, it appears to be a basic feature that has always been missing from Twitter until recently. In April 2022, Elon Musk offered to buy Twitter for $43 billion. Shortly before offering to buy Twitter, Elon asked the world:
Do you want an edit button?
— Elon Musk (@elonmusk) April 5, 2022
The question of an edit button has been asked many times before. Back in 2020, In a Q&A video for Wired, Jack Dorsey said in response to questions about whether Twitter would ever get an edit button, he said: “we’ll probably never do it”.
So why has such a seemingly basic feature alluded Twitter for so long?
In this blog post, I explore some of the challenges of adding an edit button to Twitter from a product and technical perspective; and why adding an edit button to Twitter isn't as simple as "just add a button".
The Product Considerations
Whilst adding an edit button seems like an entirely reasonable request, there are several product-oriented reasons why an edit button may not be desirable:
- According to Jack Dorsey, Twitter's original design focused on achieving a similar vibe to sending an SMS — "We started as an SMS, text message service. And as you all know, when you send a text, you can't take it back," he says. "We wanted to preserve that vibe, that feeling, in the early days."
- What happens if someone edits a tweet after people have started liking or replying to the tweet? The integrity of the conversation then becomes compromised. Any likes or replies authored against the original tweet may become invalid if the user edits the tweet because editing the tweet could alter the context and meaning of the message.
These product considerations go a step further, as they need to be viewed in the context of the technical challenges. Often, the priority of implementing a feature is influenced by the benefit the feature would provide and the trade-off in the cost of developing the feature.
As we will explore in the next section, editing tweets at Twitter's scale is not easy. Given the technical challenges combined with the product implications of editing a tweet, it makes it easier to see why an edit feature may not be considered worth the effort.
The Technical Challenge
The challenges of editing a tweet are linked to how Twitter timelines work and the challenges that can occur with reading and writing data at scale. We will therefore dig into some of the background of how Twitter works and the different paradigms for data storage so that we can get to the heart of why adding an edit button presents a significant technical challenge.
The Nature of Twitter
One of the first things for us to understand is the nature of Twitter and the pattern of user behaviour. Whilst these stats are quite old (~2013) and the actual numbers will have increased, they show a clear split between users' behaviour:
- 300,000 pull-based timeline requests per second (25.9 billion per day)
- 3,935 tweets per second (340M tweets per day)
The numbers show that on Twitter, users spend more time reading tweets than writing by several orders of magnitude. As a result, Twitter needs to optimise how it works to deal with the primary user activity of reading tweets.
Twitter operates at a truly impressive scale. Servicing 300,000 timeline requests per second and ~4,000 writes per second is going to bring about a unique set of performance and operational challenges that won't exist in smaller scale systems.
Targeted vs Queried Timelines
Twitter has two types of timelines:
- Targeted
The "Home" timeline of a given user in Twitter is a targeted timeline because the contents of the timeline is targeted based on the people that they follow. - Queried
A queried timeline occurs when a user performs a search.
Searching at Twitter's scale brings about its own set of challenges. To keep things simple, this discussion will focus on the challenges of targeted timelines.
Targeted timelines consist of predictable content. A user on Twitter will have people who they follow and the tweets of people they follow comprise their timeline activity. It is these targeted timelines that are requested 300,000 per second.
Read-Cheap/Write-Expensive vs Read-Expensive/Write-Cheap
When data needs to be persisted and retrieved in a system, it can often sit somewhere on a spectrum depending on how the data is stored, how the system is used and the architectural concerns.
In the rest of this section I will look contrast the differenced between the two extreme ends of this spectrum. I will pick an example or two that illustrate the point, not that alternative or better examples may also exist. This post will touch on a number of different technical topics at a reasonably high level to avoid getting bogged down in individual topics.
Read-Expensive/Write-Cheap
Most operational systems can often end up being read-expensive/write-cheap unless a specific focus is given to achieving a different architecture. This is quite a generalisation, but a read-expensive/write-cheap architecture shares many of the same traits that come from using a normalised data structure.
Relational databases and normalisation bring about many advantages:
- Redundant data is de-duplicated
- Data consistency and data integrity are more easily maintained because of thhe lack of duplication
- Inconsistency anomilies from insert, update and delete operations are mininimised due to elimating redundant data
- Data storage is optimised due to a lack of redundant data.
- Write operations are cheaper when compared to alternative approaches that may introduce redundancy in the data stored.
These are all good advantages to have in the design of a system, however they do come at a cost:
- The number of tables required by the system usually increases as the information modelled by the system increases due to redundant data de-duplication
- Read operations can be more intensive as data has to be joined from different tables
Typically, a normalised relational database will give you a Read-Expesnive/Write-Cheap architecture. This is what such a datbase schema could look like for twitter:
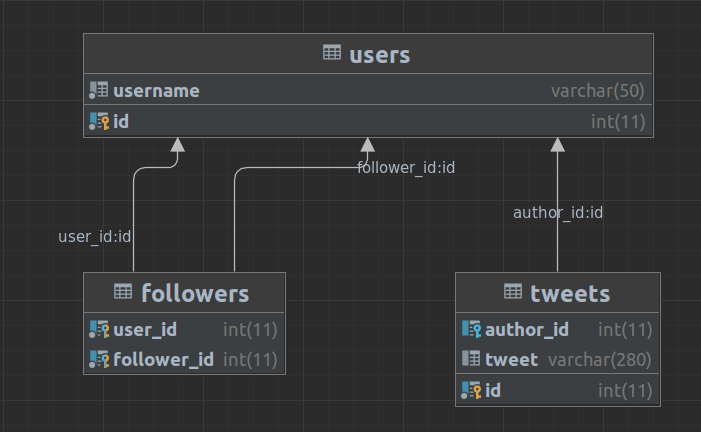
Now this is an over simplified example. but it's enough to prove the point. At low volumes of hundreds, thousasnds or hundreds of thousands of tweets this will perform fairly well. But if we get to Twitter's scale where the database is growing by 340 million tweets per day this simply won't coupe.
With a data structure such as this lets take a look at what it would take to query this to pull back tweets for a users timeline:
SELECT
followers.user_id, followers.follower_id, tweets.id, tweets.author_id, tweets.tweet, users.username
FROM
followers
LEFT OUTER JOIN
tweets ON followers.follower_id=tweets.author_id
INNER JOIN
users on tweets.author_id = users.id
WHERE
followers.user_id = CEIL(RAND() * 50000)
LIMIT 100;In this crude example I am running this query against a database with 5,000,000 tweets, 50,000 users and 37.1 million follower relationships (an average of 742 followers per user) between those 50,000 users.
The above query will pull back the first 100 tweets for one of the 50,000 users at random.
The table schema I am using is very basic, every primary key and foreign key has an index. The query is also fairly basic too, but querying and joining large tables is expensive.
Running this query typically takes a good few seconds
100 rows retrieved starting from 1 in 2 s 586 ms (execution: 2 s 563 ms, fetching: 23 ms)This is a bit of a crude example, but the goal is to prove the point that a data structure like this that is "write-cheap" and normalised comes at the cost that it can be read expensive.
To some people, ~2.5 seconds may not seem slow, but this is one user requesting 100 tweets. Increase the limit to 500 or 1000 and the query time quickly rises to over 10 seconds or 25 seconds respecively. And remember that Twitter is dealing with 300,000+ of these kind of queries every second...
An approach like this has all the benefits that we defined at the start of this section, but even when a basic schema like this is well index, at scale, pulling back a users home timeline is like trying to find a needle in a very big haystack.
Read-Cheap/Write-Expensive
At the opposite end of the spectrum is a Read-Cheap/Write-Expensive approach. This architecture can often be typical of analytical systems or where read and query performance is important. As the name suggests the cheap reads comes at the expensive of additional write operations and duplication of data.
As a result, read-cheap/write-expensive architectures typically share many of the advantages that come with a denormalised data structure:
- Faster execution of queries due to introducing redundancy in data.
- Related data is denormalised and duplicates which prevents the need for join queries.
- A denomalised structure can end up with fewer tables or collections because relationships in the model don't have to be normalised into joining tables
- Due to data redundancy systems that store denormalised data often favour eventual-consistency, therefore any overheads of the system enforcing integrity are reduced which also means that these systems can more easily achieve higher availability that systems that deal with normalised data structures.
- Systems that store denomalised data structures are often easier to scale horizontally when comparted to noramlised data stores such as relational databases because enforcing atomic and consistent operations is not a primary concern of denormalised stores.
As you would expect, a denomalised data structure does have a number of costs and drawbacks:
- Write operations can be more expensive because data is duplicated in different places
- Denomalised data structures are typically more wasteful on storage and disk space due to the duplication.
- Denormalised data structures are not well suited to systems where data integrity and consistency is critical due to the eventual-consistency nature of a denomalised data structure.
NoSQL data stores (e.g. MongoDB, AWS DynamoDB, Azure Table Storage) are good examples of systems that are designed to store denomalised data.
Let's look at Azure Table Storage (a NoSQL key-value store) as our contrasting example to the relational database that we looked at previously. To make this a fair comparison I am using the same dataset of 5,000,000 tweets, 50,000 users and 37.1 million follower relationships.
Azure Table Storage stores data in partitions, and each data item is addressable using a PartitionKey and a RowKey. A partition is a collection is entities that have the same PartitionKey. A partition will always be served from one server, and a partition server could serve more than one partition.
Azure Table Storage like most NoSQL systems, is favouring horizontal scaling, as partitions are scaled out across partition servers rather than having a small number of expensive servers where the resources have to be scaled vertically (increasing RAM, CPU, etc).
Picking a sensible value for the PartitionKey is important. The greater the cardinality of our PartitionKey values, the more scalable the system will be as different partition requests will be load-balanced between different partition servers.
In our Twitter example, let's use the username as the PartitionKey and the RowKey can be the ID of the tweet. As a result, each partition will represent a home timeline for a given user.
When someone publishes a new tweet, in our relational database example we would insert a single tweet record into our tweets table, and we would have to use joins between our users, followers and tweets table to bring back a timeline for a given user.
In a Read-Cheap/Write-Expensive architecture, we will have multiple write operations to perform when a user tweets. Rather than inserting a single tweet into a single tweets data store, we will instead need to write the tweet to each followers timeline partition.
Let's say we have John, who is followed by Emma, David and Geroge. When John tweets, the same tweet will be written to Emma's timeline partition, David's timeline partitoon and George's timeline partition. This is the write-expensive part of this approach.
However, imagine we need to pull back Emma's timeline. Rather than doing an expensive query that joins 3 tables together to figure out which tweets apply to her, all we need to do is query for the tweets in her home timeline partition.
Running a query like this on Azure Table Storage is able to return all the tweets for a given user at random in 0.1266697s (on average):
PartitionKey eq '[USERNAME-GOES-HERE]'This approach of duplicating tweets out to the timeline of every single follower is the "fanout" approach that Raffi Krikorian describes in his Real-Time Delivery Architecture at Twitter talk on YouTube. As you'd expect, what I've outlined here trivialises what Twitter actually does as there is much more that has to go into making a service of Twitter's scale work the way that it does.
With an approach like this publishing a tweet has a complexity of O(n) where n is the number of followers. Put more simply, for each follower you have, a write operation needs to take place. The more followers you have, the slower this gets.
The major benefit however, is that the complexity for a user wanted to refresh their tweet timeline is O(1) because we need to perform a single read operation to pull back the tweets from the users timeline partition.
When you have 300,000 timeline requests per second verses 3,935 new tweets per second, the trade-off here between write-expensive and read-cheap is well balanced.
The only exception to this is "celebrities" or those with over 2 million followers. As you'd expect, fanning out a tweet through 2 million write operations will take some time to propogate. As Raffi outlines in his talk, Twitter actually uses a hybrid approach where Read-Cheap/Write-Expensive works for most uses, but for users over 2 million followers they actually use something more like the Read-Expensive/Write-Cheap approach and "celebrity" tweets are merged into a users timeline at the point that it is requested.
An Edit Button Isn't Simple
Adding an edit button to Twitter sounds easy, but it really isn't.
Twitter duplicates tweets to deal with the unique performance challenges they experience when they're having to process 300,000 timeline requests per second. When a tweet is originally published there will be some delay before every follower gets to see the tweet. For the most part, that's ok, because tweets are currently immutable and is anyone really going to notice if a tweet takes a few seconds or minutes to propogate to them? This is a use case where eventual consistency works well.
If, however, a tweet was edited that edit would have to be propogated amongst those duplicated tweets.
As a result you could end up with some followers engaging in the original tweet before the edited version of the tweet has been propogated to their timeline. Followers could be replying to the thread based on either the original tweet content or the edited content. From a product perspective this could be undesirable because the integrity of a conversation could be manipulated by allowing users to edit tweets and the editing process will unlock a number of challenges that comes from an architecture that relies on eventual consistency.
Summary
Twitter operates at such a vast scale that performance is critical, and nature of the performance challenge is rather unique. Performance often forms an iron triangle with time and cost.
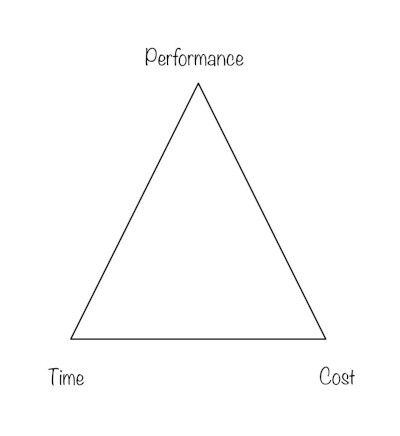
Adding an edit button to Twitter isn't as simple as just adding an edit button and textbox for the user to edit the tweet in. If twitter was to add an edit button they'd have to consider how they did this in a way that was performant for them, and this raises a big question of: would such a feature be worth the time and cost investment?
Towards the end of September, whilst I was finishing the first version of this blog post, Twitter released the first version of the edit button, which has the following limitations:
- You can only edit within 30 minutes of posting the original tweet
- The tweet can only be edited up to 5 times
- It is a paid-for feature for Twitter Blue users
It would not surprise me if the decision to enforce these limitations is partly product driven, but also partly technical.